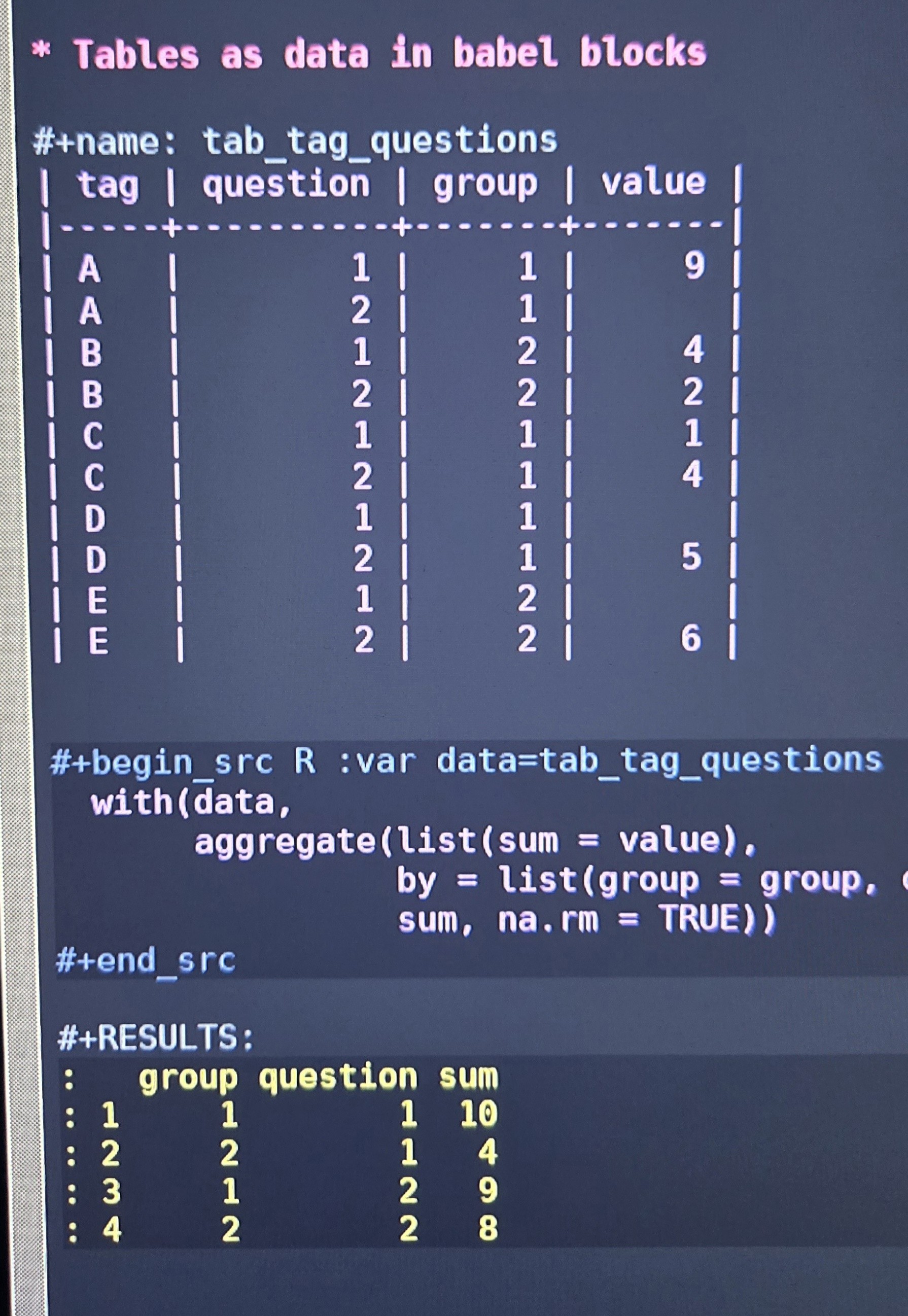
Today, @edumerco motivated me to give a deeper look to #Org mode and #Emacs #Lisp for processing data as a reproducible computational notebook. It reminds me this great MOOC [1]. 🤩
And today I learn more about #Sociocracy thanks @edumerco! Well, the concept of #Guix teams needs more love. 😍
Bah the kind of day when you feel part of something. 🥳
Thanks @bzg for the connection. 😁
1: https://www.fun-mooc.fr/en/courses/reproducible-research-methodological-principles-transparent-scie
")
Dear @zimoun , thank you for such a rich meeting and sharing your experience with #ReproducibleResearch and #guix for this #tem25 thesis . :)
#orgmode Babel (blocks of code calling anything integrated with the text and images) are great for #LiteraryProgramming and reprod. research.
Also, thank you for your mention of #ggplot2 that @ansate nailed too a little later. :)
Thanks also to @bzg too. 🙏
Re #PeerGovernance, I'd be delighted to share my experience with the guix community anytime.