

We'll see how I feel in the morning, but for now i seem to have convinced myself to actually read that fuckin anthropic paper
Discussion
Loading...

@jenniferplusplus Thank you for this thread
I just
I'm not actually in the habit of reading academic research papers like this. Is it normal to begin these things by confidently asserting your priors as fact, unsupported by anything in the study?
I suppose I should do the same, because there's no way it's not going to inform my read on this


@jenniferplusplus it's not a great lit review/paper in terms of connecting to broader literature; that is however typical for software research (not for more empirical fields like psychology imho)
")

@jenniferplusplus no, usually academic studies have a null hypothesis of "the effect we're trying to study does not exist" and are required to provide evidence sufficient to reject that hypothesis
"AI" is not actually a technology, in the way people would commonly understand that term.
If you're feeling extremely generous, you could say that AI is a marketing term for a loose and shifting bundle of technologies that have specific useful applications.
I am not feeling so generous.
AI is a technocratic political project for the purpose of industrializing knowledge work. The details of how it works are a distant secondary concern to the effect it has, which is to enclose and capture all knowledge work and make it dependent on capital.


@jenniferplusplus
Sympathies. It's difficult to explain that cognition and reasoning are required for intelligence to generations of people who have had it drummed into them that amassing facts make them "smart".

@jenniferplusplus I feel like the term has come to encompass every technology we've built in pursuit of AI even when it's nowhere close on its own.
It's a marketing thing very much akin to the "space age materials" and other bullshit hype of yesteryear. It's just a different kind of plastic, it's not "space technology".
@gooba42 yeah, basically. I think the role it plays in society is more like "free markets" or "national security". But in terms of how rigorously it connects to any specific object or process, "space age material" is a good model

@jenniferplusplus I heard or read that someone said, "A manager is a person who thinks anything they don't know how to do must be easy". They've just extended that to 'thinking' itself. If there's a demand, some TechBro will pretend to have a very expensive solution. This time it costs the environment, by using up all the cheap renewable energy gains, to keep fossils in the game, so it's Win-Win for terrible people.

@jenniferplusplus ai is also an #enshittification multiplyer @doctorrow


@jenniferplusplus "The details of how [the AI industry works] are a distant secondary concern to the effect it has, which is to enclose and capture all knowledge work and make it dependent on capital."
Tax, anyone?



@jenniferplusplus
bookmarked for future reference, boosting is not enough



@jenniferplusplus How about not just capital, but also permission?
Imagine a world in which "AI" is actually successful: it is widely, maybe even largely universally, adopted, and it actually works to deliver on its promises. (I *said* "imagine"! Bear with me.) In such a world, what happens to someone (person, company, country, whatever slicing you want to look at) who is *denied access to* this technology for whatever reason?
The power held by those in control of allowing access to that tech…
@mkj Yeah, same thing. You can't use industrial machines without the permission of the owner.
So, back to the paper.
"How AI Impacts Skill Formation"
https://arxiv.org/abs/2601.20245
The very first sentence of the abstract:
> AI assistance produces significant productivity gains across professional domains, particularly for novice workers.
1. The evidence for this is mixed, and the effect is small.
2. That's not even the purpose of this study. The design of the study doesn't support drawing conclusions in this area.
Of course, the authors will repeat this claim frequently. Which brings us back to MY priors, which is that this is largely a political document.
")
@jenniferplusplus oh gods I need to read this.
@hrefna Im finding it frustrating, mainly

@jenniferplusplus It's less a claim and more an intentionally-unsubstantiated background premise which the supposed research will treat as an assumed truth.
@dalias Honestly, yes. I suspect the purpose of this paper is to reinforce that production is a correct and necessary factor to consider when making decisions about AI.
And secondarily, I suspect it's establishing justification for blaming workers for undesirable outcomes; it's our fault for choosing to learn badly.
And now for a short break
I have eaten. I may be _slightly_ less cranky.
Ok! The results section! For the paper "How AI Impacts Skill Formation"
> we design a coding task and evaluation around a relatively new asynchronous Python library and conduct randomized experiments to understand the impact
of AI assistance on task completion time and skill development
...
Task completion time. Right. So, unless the difference is large enough that it could change whether or not people can learn things at all in a given practice or instructional period, I don't know why we're concerned with task completion time.
Well, I mean, I have a theory. It's because "AI makes you more productive" is the central justification behind the political project, and this is largely a political document.
![[ade]](https://cdn.masto.host/kdesocial/accounts/avatars/114/406/102/412/128/422/original/80826cd9f3ebd519.png "[ade]")

@jenniferplusplus you have inspired me to read it as well (over beer and pizza) and .. yeah, what she said. I think i gave up before the results section. i did feel that the prep-work to calibrate the experiment (e.g the local item dependence in the quiz) was pretty well done, but i will defer to any sociologist who says otherwise.
Why is all the so-called productivity in the paper at all?
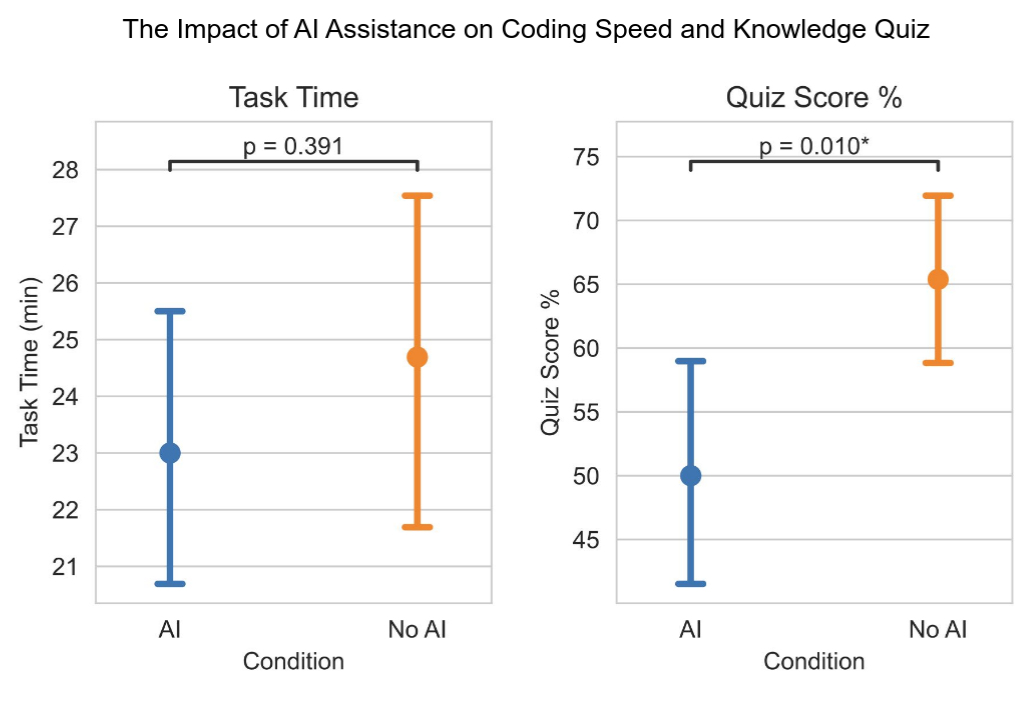
> We find that using AI assistance to complete
tasks that involve this new library resulted in a reduction in the evaluation score by 17% or two grade
points (Cohen’s d = 0.738, p = 0.010). Meanwhile, we did not find a statistically significant acceleration in
completion time with AI assistance.
I mean, that's an enormous effect. I'm very interested in the methods section, now.
> Through an in-depth qualitative analysis where we watch the screen recordings of every participant in our
main study, we explain the lack of AI productivity improvement through the additional time some participants
invested in interacting with the AI assistant.
...
Is this about learning, or is it about productivity!? God.
> We attribute the gains in skill development of the control group to the process of encountering and subsequently resolving errors independently
Hm. Learning with instruction is generally more effective than learning through struggle. A surface level read would suggest that the stochastic chatbot actually has a counter-instructional effect. But again, we'll see what the methods actually are.
Edit: I should say, doing things with feedback from an instructor generally has better learning outcomes than doing things in isolation. I phrased that badly.
4+ more replies (not shown)
They reference these figures a lot, so I'll make sure to include them here.
> Figure 1: Overview of results: (Left) We find a significant decrease in library-specific skills (conceptual
understanding, code reading, and debugging) among workers using AI assistance for completing tasks with a
new python library. (Right) We categorize AI usage patterns and found three high skill development patterns
where participants stay cognitively engaged when using AI assistance
2 media
> As AI development progresses, the problem of supervising more and more capable AI systems becomes more difficult if humans have weaker abilities to understand code [Bowman et al., 2022]. When complex software tasks require human-AI collaboration,
humans still need to understand the basic concepts of code development even if their software skills are
complementary to the strengths of AI [Wang et al., 2020].
Right, sure. Except, there is actually a third option. But it's one that seems inconceivable to the authors. That is to not use AI in this context. I'm not even necessarily arguing* that's better. But if this is supposed to be sincere scholarship, how is that not even under consideration?
*well, I am arguing that, in the context of AI as a political project. If you had similar programs that were developed and deployed in a way that empowers people, rather than disempowers them, this would be a very different conversation. Of course, I would also argue that very same political project is why it's inconceivable to the authors, soooo
And then we switch back to background context. We get a 11 sentences of AI = productivity. Then 3 sentences on "cognitive offloading". 4 sentences on skill retention. And 4 on "over reliance". So, fully 50% of the background section of the "AI Impacts on Skill Formation" paper is about productivity.
Chapter 3. Framework.
Finally.
Paraphrasing a little: "the learning by doing" philosphy connects completing real world tasks with learning new concepts and developing new skills. Experiental learning has also been explored to mimic solving real world problems. We focus on settings where workers must acquire new skills to complete tasks. We seek to understand both the impact of AI on productivity
and skill formation. We ask whether AI assistance presents a tradeoff between immediate productivity and longer-term skill development or if AI assistance presents a shortcut to enhance both.
Right. There it is again: productivity. Even within this framing, there are at least 3 more possibilities. That AI does not actually increase productivity; that AI has no effect at all; or that AI improves learning only. I think it's very telling that the authors don't even conceive of these options. Particularly the last one.
But I'm becoming more and more convinced that the framing of productivity as an essential factor to measure and judge by is itself the whole purpose of this paper. And, specifically, productivity as defined by production output. But maybe I'm getting ahead of myself.
And now we have actual research questions! It feels like it shouldn't take this long to get these, but w/e
1. Does AI assistance improve task completion productivity when new skills are required?
2. How does using AI assistance affect the development of these new skills?
We'll learn how the authors propose to answer these questions in the next chapter: Methods.
But first, there is a 6 year old in here demanding I play minecraft, and I'd rather do that.
To be continued... probbaly
Chapter 4. Methods.
Let's go
First, the task. It's uh. It's basically a shitty whiteboard coding interview. The assignment is to build a couple of demo projects for an async python library. One is a non-blocking ticker. The other is some I/O ("record retrieval", not clear if this is the local filesystem or what, but probably the local fs) with handling for missing files.
Both are implemented in a literal white board coding interview tool. The test group gets an AI chatbot button, and encouragement to use it. The control group doesn't.
/sigh
I just. Come on. If you were serious about this, it would be pocket change to do an actual study
Found it! n=52. wtf. I reiterate: 20 billion dollars, just for this current funding round, and they only managed to do this study with 52 people.
But anyway, let's return to the methods themselves. They start with the design of the evaluation component, so I will too. It's organized around 4 evaluative practices they say are common in CS education. That seems fine, but their explanation for why these things are relevant is weird.
1. Debugging. According to them "this skill is curcial for detecting when AI-generated code is incorrect and understanding why it fails.
Maybe their definition is more expansive than it seems here? But it's been my experience, professionally, that this is just not the case. The only even sort-of reliable mechanism for detecting and understanding the shit behavior of slop code is extensive validation suites.
2. Code Reading. "This skill enables humans to understand and verify AI-written code before deployment."
Again, not in my professional experience. It's just too voluminous and bland. And no one has time for that shit, even if they can make themselves do it. Plus, I haven't found anyone who can properly review slop code, because we can't operate without the assumptions of comprehension, intention, and good faith that simply do not hold in that case.
3. Code writing. Honestly, I don't get the impression they even understand what this means. They say "Low-level code writing, like remembering the syntax of functions, will be less important with further integration of AI coding tools
than high-level system design."
Neither of those things is a meaningful facet of actually writing code. Writing code exists entirely in-between those two things. Code completion tools basically eliminate having to think about syntax (but we will return to this). And system design happens in the realm of abstract behaviors and responsibilities.
4. Conceptual. As they put it, "Conceptual understanding is critical to assess whether AI-generated code uses appropriate design patterns that adheres to how the library should be used.
IIIIIII guess. That's not wrong, exactly? But it's such a reverse centaur world view. I don't want to be the conceptual bounds checker for the code extruder. And I don't understand why they don't understand that.
So anyway, all of this is, apparently, in service to the "original motivation of developing and retaining the skills required for supervising automation."
Which would be cool, I'd like to read that study, because it isn't this one. This study is about whether the tools used to rapidly spit out meaningless code will impact one's ability to answer questions about the code that was spat. And even then, I'm not sure the design of the study can answer that question.
I guess this brings me to the study design. I'm struggling a little to figure out how to talk about this. The short version is that I don't think they're testing any of the effects they think they're testing.
So, they start with a warmup coding round, which seems to be mostly to let people become familiar with the tool. That's important, because the tool is commercial software for conducting coding interviews in a browser. They don't say which one, that I've seen.
Then they have two separate toy projects that the subjects should complete. 1 is a non-blocking ticker, using a specific async library. 2 is some async I/O record retrieval with basic error handling, using the same async library.
And then they take a quiz about that async library.
But there's some very important details. The coding portion and quiz are both timed. The subjects were instructed to complete them as fast as possible. And the testing platform did not seem to have code completion or, presumably, any other modern development affordance.
Given all of that, I don't actually think they measured the impact of the code extruding chatbots at all. On anything. What they measured was stress. This is a stress test.
And, to return to their notion of what "code writing" consists of: the control subjects didn't have code completion, and the test subjects did. I know this, because they said so. It came up in their pilot studies. The control group kept running out of time because they struggled with syntax for try/catch, and for string formatting. They only stopped running out of time after the researchers added specific reminders for those 2 things to the project's instructions.
So. The test conditions were weirdly high stress, for no particular reason the study makes clear. Or even acknowledges. The stress was *higher* on the control group. And the control group had to use inferior tooling.
I don't see how this data can be used to support any quantitative conclusion at all.
Qualitatively, I suspect there is some value in the clusters of AI usage patterns they observed. But that's not what anyone is talking about when they talk about this study.
And then there's one more detail. I'm not sure how I should be thinking about this, but it feels very relevant. All of the study subjects were recruited through a crowd working platform. That adds a whole extra concern about the subject's standing on the platform. It means that in some sense undertaking this study was their job, and the instruction given in the project brief was not just instruction to a participant in a study, but requirements given to a worker.
I know this kind of thing is not unusual in studies like this. But it feels like a complicating factor that I can't see the edges of.
But now it's 1am. I may pick this up tomorrow, I'm not sure. If I do, the next chapter is their analysis. Seems like there would be things in there that merit comment
Actually, hang on. One more thing occurred to me. Does this exacerbate the difficulty of replication, given that the simple passage of time will render this library no longer new?
And now I'm done for the night, for real
I might get back to this after breakfast.
There's 2 particular things i keep thinking about.
1. The quiz scores dropped significantly for people who started out using the chatbots in interrogatory ways and then evolved to having it do major code generation, as compared to people who persisted in their interrogative use. Or as compared to people who used it for major generation, but followed up with interrogation.
2. Even with syntax reminders, the control group had difficulty completing the coding problems due to struggling with syntax. I want to know if this had an observable effect on the quiz scores.
They didn't really explore either phenomenon. It also doesn't seem like they included enough data that i could do much of an analysis myself. And I'm not sure I would want to, anyway
Let's finish this off.
They had like ~~2~~ 4 paragraphs at the end of the results for a quantitative analysis. And, as it turns out, I also don't have much more to say about this thing, quantitatively. I continue to think that the study design doesn't actually allow for meaningful comparisons between the control and test groups. That sucks. Maybe they should talk to some methods people, I dunno. I can think of one I'd recommend.
Qualitatively, I think there are things worth discussing. And it seems the authors agree, because there's 7 pages of it.
They identified 4 "axes" of interaction with the AI that they think are explanatory. As they put it:
- AI Interaction Time: The lack of significant speed-up in the AI condition can be explained by how some participants used AI. Several participants spent substantial time interacting with the AI assistant, spending up to 11 minutes composing AI queries in total
- Query Types: The study participants varied between conceptual questions only, code generation only,
and a mixture of conceptual, debugging, and code generation queries. Participants who focused on
asking the AI assistant debugging questions or confirming their answer spent more time on the task
- Encountering Errors: Participants in the control group (no AI) encountered more errors; these errors
included both syntax errors and Trio errors (Figure 14). Encountering more errors and independently
resolving errors likely improved the formation of Trio skills (note, Trio is the library that was the focus of the test problems)
- Active Time: Using AI decreased the amount of active coding time. Time spent coding shifted to time spent interacting with AI and understanding AI generations (Figure 16).
I continue to find this frustrating, because they absolutely will not let go of notions like time to completion or rate of output as being meaningful, or even vital. But this is supposed to be a study about learning outcomes. I'm not an expert on the latest in learning/teaching research, but I don't think those are useful measures. Please, correct me if I'm wrong, though.
They also have remarkably little to say about the control group in this section, and I think _that_ says a lot.
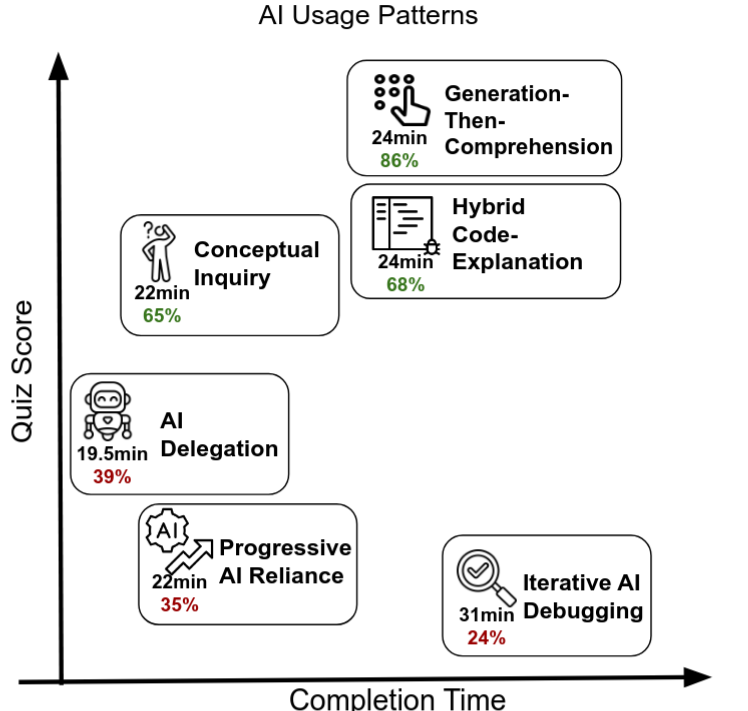
Still, they then identified 6 clusters of interaction patterns with the AI that correlated with performance and related in varying degrees to those axes.
Personally, I think I would call it 5 patterns, plus a group that moved from 1 pattern to another. But maybe that's not an important distinction.
They broadly fell into low-scoring and high-scoring groups. The low scoring group was:
- AI delegation. Just having the chatbot generate all the code.
- "Progressive AI Reliance". Or, starting with conceptual inquiry, and then later just having the chatbot generate everything.
- Iterative AI Debugging. Just having the chatbot generate all the code, and then just showing the chatbot whatever errors resulted and instructing it to fix the problem.
What I find *really* interesting here is that the group who started with what they call conceptual inquiry and then moved to delegation scored _30 percent_ lower on the quiz than the group who only engaged in conceptual inquiry.
That is an ENORMOUS effect for a tiny intervention. They actually performed comparably the group that engaged in pure delegation the whole time. I don't see any discussion of this from the authors, and that also sucks.
I might have expected the initial approach that was more oriented around understanding would have some protective effect against the switch to a production orientation. I also wonder if it reflects a disengagement with the task? Apparently the authors don't share my curiosity.
Then there are the high-scoring patterns:
- "Generation then comprehension". Generate code, and then ask followup questions about it.
- "Hybrid code-explanation". Generate code and simultaneously ask for explanation.
- "Conceptual inquiry". Don't generate code, just ask questions for understanding.
The authors propose that "spending time" and "encountering errors" do a lot to explain the difference in quiz scores. The relative results from these groups make me doubt that. I suspect that the actual differentiator is having assumptions revealed and invalidated. The generate-then-follow-up pattern is the only one of the three that actually offers a chance to incorporate some result from a change into the explanation of the change. This group scored 16% - 19% higher than the other two, for nearly the same amounts of time spent on the task.
Finally, I think I'll leave you with some of the feedback given by the control group:
- "This was a lot of fun but the recording aspect can be cumbersome on
some systems and cause a little bit of anxiety especially when you can’t
go back if you messed up the recording."
- "I think I could have done much better if I could have accessed the coding tasks I did at part 2 during the quiz for reference, but I still tried my best. I ran out of time as the bug-finding questions
were quite challenging for me."
- "I spent too much time on this quiz, but that was due to my time management.
Even if I hadn’t spent too much time on the first part, though, it still
would have been a tight finish for me in the 30 minute window I think."
To me, these read like stress. It's so disappointing that the study was designed in such a stressful way. Even moreso that the subject's stress doesn't seem to have been considered as a factor at all. That plus the tooling handicap of the control group make it impossible to draw the kind of conclusions that the authors and Anthropic seem to be doing.
/end
Actually, one last thing.
I don't think this study was well designed, but I don't want to go much farther than that.
Some people have made something out of the paper not being peer reviewed. That's not a secret, though. This is arxiv, it's a prepublication host.
Also, I glanced at the lead author's other work, and I get the impression that she's just not accustomed to working with human subjects. I think that's hubris, but not malice. It's just the standard attitude in tech that being good at computer touching qualifies one to do virtually anything else they want.


@jenniferplusplus "not accustomed to working with human subjects" 😬😬😬
@mayintoronto and that's why the study design is basically one round of a normal tech interview

@jenniferplusplus I like the fact that their own research doesn't fit their lazy claim you reference, and they spend a lot of time trying to work out how the claim can be true, even though their own evidence is against it (and more in line with the mixed evidence in the literature, as you say).

@jenniferplusplus No it is not. That kind of thing is left to the realm of "self-publishing". Was this thing peer reviewed?
@seanwbruno It is not. https://arxiv.org/abs/2601.20245
@jenniferplusplus You have entirely more stamina than I have. I just read the first sentence of the abstract and emitted a guffaw and exclaimed, out loud for the spouse to hear, "Citation needed!".
