
Tommi 🤯
boosted

IL FEDIVERSO E I SOCIAL MAINSTREAM
In questo post per la rubrica aperiodica #Define, spieghiamo brevemente cos'è e come funziona il #Fediverso, per poi passare a parlare delle acclarate insidie e scelleratezze dei social mainstream.
https://www.fanrivista.it/2026/02/breve-definizione-di-fediverso.html
In aggiunta e in esclusiva sui nostri canali del Fediverso, un vodcast di approfondimento ricavato da un intervento di @tommi a @reclaimthetech
Versione VIDEO: https://peertube.uno/w/e8XUXnD44VouXnJWkEUCpK
Versione PODCAST: https://open.audio/library/tracks/455557/

IL FEDIVERSO E I SOCIAL MAINSTREAM
In questo post per la rubrica aperiodica #Define, spieghiamo brevemente cos'è e come funziona il #Fediverso, per poi passare a parlare delle acclarate insidie e scelleratezze dei social mainstream.
https://www.fanrivista.it/2026/02/breve-definizione-di-fediverso.html
In aggiunta e in esclusiva sui nostri canali del Fediverso, un vodcast di approfondimento ricavato da un intervento di @tommi a @reclaimthetech
Versione VIDEO: https://peertube.uno/w/e8XUXnD44VouXnJWkEUCpK
Versione PODCAST: https://open.audio/library/tracks/455557/


set(CMAKE_CXX_STANDARD 17) is set in CMake. Oh, and I believe this same code compiled on GCC before, implying something changed with headers or header order.
My questions, I think, are:
1. This smells to me like a #define somewhere doing something weird. Does it smell like that to you too, or could something else be happening?
2. Can I induce CMake to spit out the gcc -E output so I can see what the preprocessor is turning this code into?
(2/2)
Having a C++ hell problem.
There's a namespace named "vendor", containing a class named "ClassName", containing an enum "EnumName", containing a value named "Success".
There's code that compiles on Windows with MSVC and on MacOS with Clang. But on Linux with GCC, it fails; if I say vendor::ClassName::Success it says "expected unqualified-id before numeric constant" on Success and if I say "vendor::ClassName::EnumName::Success" it says "expected unqualified-id before 'int'" on EnumName.
(1/2)

set(CMAKE_CXX_STANDARD 17) is set in CMake. Oh, and I believe this same code compiled on GCC before, implying something changed with headers or header order.
My questions, I think, are:
1. This smells to me like a #define somewhere doing something weird. Does it smell like that to you too, or could something else be happening?
2. Can I induce CMake to spit out the gcc -E output so I can see what the preprocessor is turning this code into?
(2/2)
Ben Ramsey
boosted

The best static site generator is actually just one line of shell and available on any GNU system.
for filename in src/**/*.html; do; cpp -EwP "$filename" > "out/$filename"; done
This works with:
- snippets/shortcodes (e.g. #include "_header.html")
- file metadata (e.g. #define TITLE My Awesome Post)
- conditional inclusion (with #ifdef)
add -finput-charset=utf-8 and -fexec-charset=utf-8 if you'd like to use non-ASCII text.
Enjoy :P
The best static site generator is actually just one line of shell and available on any GNU system.
for filename in src/**/*.html; do; cpp -EwP "$filename" > "out/$filename"; done
This works with:
- snippets/shortcodes (e.g. #include "_header.html")
- file metadata (e.g. #define TITLE My Awesome Post)
- conditional inclusion (with #ifdef)
add -finput-charset=utf-8 and -fexec-charset=utf-8 if you'd like to use non-ASCII text.
Enjoy :P

Miguel de Icaza ᯅ🍉
boosted

// Bonfire
#define r(a)*=mat2(cos(a+vec4(0,33,11,0))),
void main(){float i,t,a,n,w,o,d=1.;for(vec3 p,q,k;i++<5e1&&d>.001;o+=d>n?d=abs(n)*.4+.05,1./d:exp(3.-length(k)*.6),t+=d*.5)for(k=normalize(vec3(P+P-R,R.y))*t,d=k.y+=6.,k.z-=15.,w=.0025,a-=a,n=.96*length(k.xz)+.27*k.y-5.34;a++<9.;w+=w)p=k,p.zx r(a*2.4)q=p,q.y-=a*T,n+=abs(dot(sin(q*.7/w),q-q+w)),p.z-=5.,p.zy r(atan(a*.18))d=min(d,max(abs(p.z+5.)-5.,max(abs(p.x)*.9+p.y*.5,-p.y)-.3));O=vec4(tanh(o*vec3(9,3,1)/5e2),1);}
// Bonfire
#define r(a)*=mat2(cos(a+vec4(0,33,11,0))),
void main(){float i,t,a,n,w,o,d=1.;for(vec3 p,q,k;i++<5e1&&d>.001;o+=d>n?d=abs(n)*.4+.05,1./d:exp(3.-length(k)*.6),t+=d*.5)for(k=normalize(vec3(P+P-R,R.y))*t,d=k.y+=6.,k.z-=15.,w=.0025,a-=a,n=.96*length(k.xz)+.27*k.y-5.34;a++<9.;w+=w)p=k,p.zx r(a*2.4)q=p,q.y-=a*T,n+=abs(dot(sin(q*.7/w),q-q+w)),p.z-=5.,p.zy r(atan(a*.18))d=min(d,max(abs(p.z+5.)-5.,max(abs(p.x)*.9+p.y*.5,-p.y)-.3));O=vec4(tanh(o*vec3(9,3,1)/5e2),1);}
Joel Michael
boosted

@jpsays @shanselman @alf149 @thomasfuchs
```
#define BEGIN {
#define END }
```
I don't know whether to find this adorable or be horrified.
@shanselman @alf149 @thomasfuchs
:)
"To whoever winds up maintaining this, I will apoligize in advance. I had just learned 'C' when writing this, so out of ignorance of the finer points of the langauge I did a lot of things by brute force. Hope this doesn't mess you up too much - MT 5/20/86"
https://github.com/microsoft/MS-DOS/blob/main/v4.0/src/CMD/FDISK/FDISK.C
@jpsays @shanselman @alf149 @thomasfuchs
```
#define BEGIN {
#define END }
```
I don't know whether to find this adorable or be horrified.

Solved! Trial-and-error indicates that you have to #define USE_KERNEL before using any system includes like #include <stdio.h>, as it appears they check for it. If you neglect to do this, you get cryptic "unresolved reference to __main" errors even when trying to build a library.
My program still doesn't work (one module is raising hundreds of "too far for size-two reloc" linker errors) but I think that's because the module is >64K and needs to be split up more, which is my own fault and a problem for tomorrow.



@SRAZKVT it's both better and worse than that. it specifically uses the STRINGLIB_CHAR macro but redefines it in source files that deal with bytes to be a char
@SRAZKVT in ucs4lib.h (i think that's utf-32 right?) it has #define STRINGLIB_CHAR Py_UCS4
i had missed this file that actually implemented the regex engine https://github.com/python/cpython/blob/main/Modules/_sre/sre_lib.h that looks much more familiar. the case statement doing what it was made for
this part in particular is fucking............it's really cool actually
/* generate 8-bit version */
#define SRE_CHAR Py_UCS1
#define SIZEOF_SRE_CHAR 1
#define SRE(F) sre_ucs1_##F
#include "sre_lib.h"
/* generate 16-bit unicode version */
#define SRE_CHAR Py_UCS2
#define SIZEOF_SRE_CHAR 2
#define SRE(F) sre_ucs2_##F
#include "sre_lib.h"
/* generate 32-bit unicode version */
#define SRE_CHAR Py_UCS4
#define SIZEOF_SRE_CHAR 4
#define SRE(F) sre_ucs4_##F
#include "sre_lib.h"
what does this mean?
/* This file is included three times, with different character settings */
that's right. they just did compile time polymorphism in 12 lines of standard C


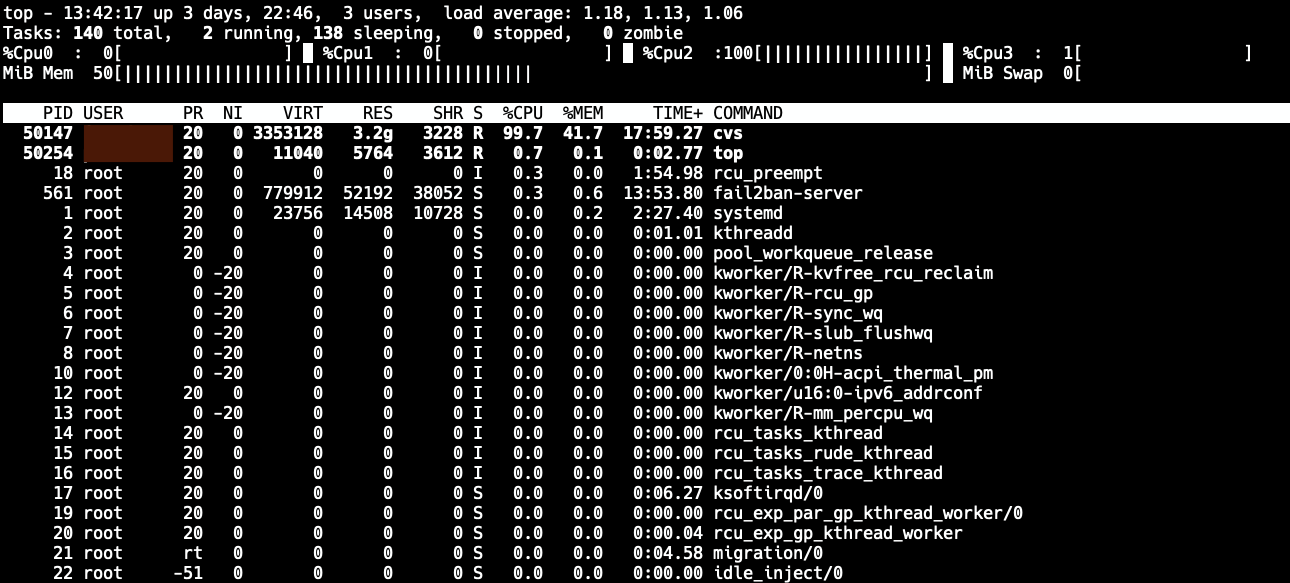
As it happens, we still use CVS in our operating system project (there are reasons for doing this, but migration to git would indeed make sense).
While working on our project, we occasionally have to do a full checkout of the whole codebase, which is several gigabytes. Over time, this operation has gotten very, very, very slow - I mean "2+ hours to perform a checkout" slow.
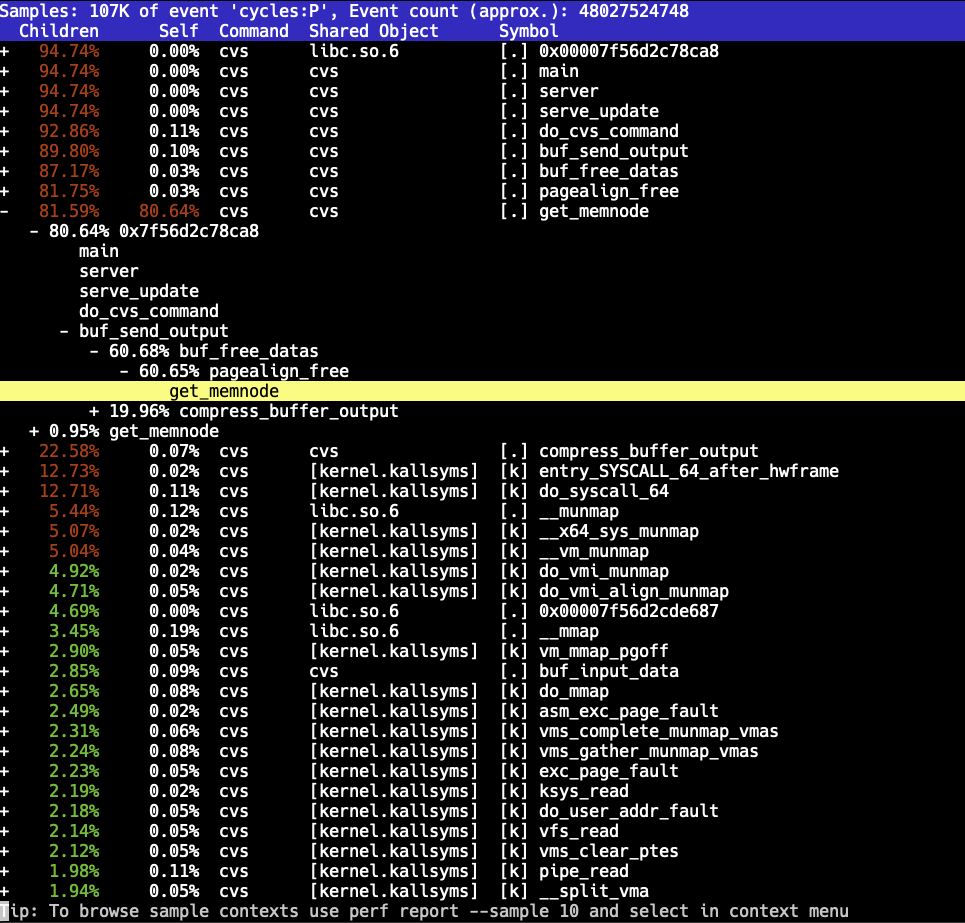
This was getting quite ridiculous. Even though it's CVS, it shouldn't crawl like this. A quick build of CVS with debug symbols and sampling the "cvs server" process with Linux perf showed something peculiar: The code was spending the majority of the time inside one function.
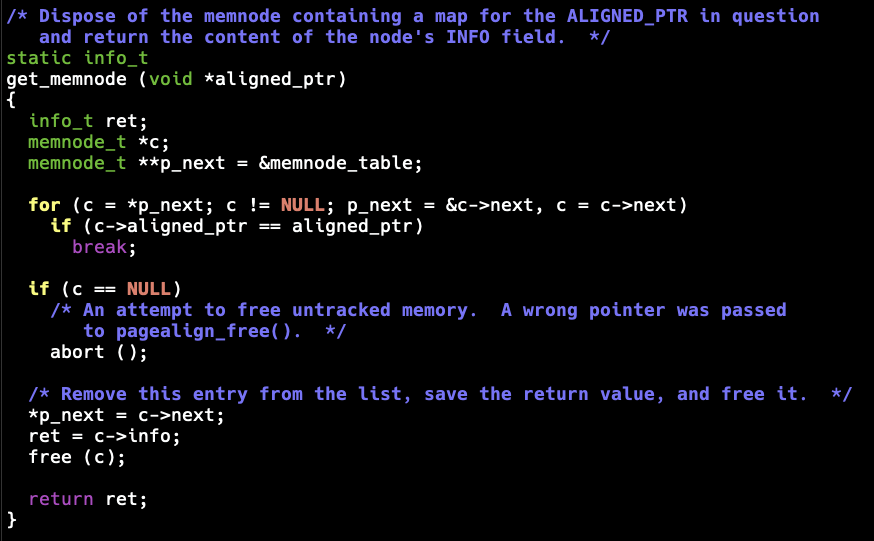
So what is this get_memnode() function? Turns out this is a support function from Gnulib that enables page-aligned memory allocations. (NOTE: I have no clue why CVS thinks doing page-aligned allocations is beneficial here - but here we are.)
The code in question has support for three different backend allocators:
1. mmap
2. posix_memalign
3. malloc
Sounds nice, except that both 1 and 3 use a linked list to track the allocations. The get_memnode() function is called when deallocating memory to find out the original pointer to pass to the backend deallocation function: The node search code appears as:
for (c = *p_next; c != NULL; p_next = &c->next, c = c->next)
if (c->aligned_ptr == aligned_ptr)
break;
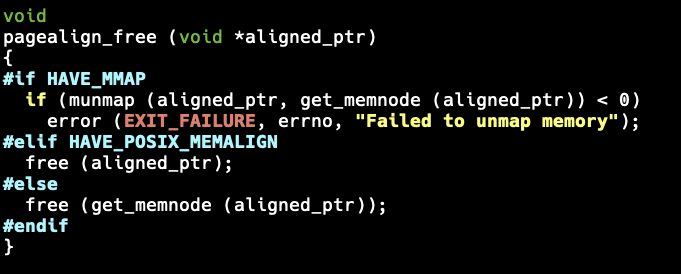
The get_memnode() function is called from pagealign_free():
#if HAVE_MMAP
if (munmap (aligned_ptr, get_memnode (aligned_ptr)) < 0)
error (EXIT_FAILURE, errno, "Failed to unmap memory");
#elif HAVE_POSIX_MEMALIGN
free (aligned_ptr);
#else
free (get_memnode (aligned_ptr));
#endif
This is an O(n) operation. CVS must be allocating a huge number of small allocations, which will result in it spending most of the CPU time in get_memnode() trying to find the node to remove from the list.
Why should we care? This is "just CVS" after all. Well, Gnulib is used in a lot of projects, not just CVS. While pagealign_alloc() is likely not the most used functionality, it can still end up hurting performance in many places.
The obvious easy fix is to prefer the posix_memalign method over the other options (I quickly made this happen for my personal CVS build by adding tactical #undef HAVE_MMAP). Even better, the list code should be replaced with something more sensible. In fact, there is no need to store the original pointer in a list; a better solution is to allocate enough memory and store the pointer before the calculated aligned pointer. This way, the original pointer can be fetched from the negative offset of the pointer passed to pagealign_free(). This way, it will be O(1).
I tried to report this to the Gnulib project, but I have trouble reaching gnu.org services currently. I'll be sure to do that once things recover.
4 media
So how does CVS use pagealign_xalloc? Like this:
/* Allocate more buffer_data structures. /
/ Get a new buffer_data structure. */
static struct buffer_data *
get_buffer_data (void)
{
struct buffer_data *ret;
ret = xmalloc (sizeof (struct buffer_data));
ret->text = pagealign_xalloc (BUFFER_DATA_SIZE);
return ret;
}
Surely BUFFER_DATA_SIZE will be something sensible? Unfortunately it is not:
#define BUFFER_DATA_SIZE getpagesize ()
So it will by create total_data_size / pagesize number of list nodes in the linear list. Maybe it's not that bad if the nodes are released in an optimal order?
The pagealign code stores new nodes always to the head of its list:
new_node->next = memnode_table;
memnode_table = new_node;
The datanodes in CVS code are however inserted into a list tail:
newdata = get_buffer_data ();
if (newdata == NULL)
{
(*buf->memory_error) (buf);
return;
}
if (buf->data == NULL)
buf->data = newdata;
else
buf->last->next = newdata;
newdata->next = NULL;
buf->last = newdata;
This creates a pathological situation where the nodes in the aligned list are in worst possible order as buf_free_datas() walks the internal list in first to last node, calling the pagealign_free:
static inline void
buf_free_datas (struct buffer_data *first, struct buffer_data *last)
{
struct buffer_data *b, *n, *p;
b = first;
do
{
p = b;
n = b->next;
pagealign_free (b->text);
free (b);
b = n;
} while (p != last);
}
In short: This is very bad. It will be slow as heck as soon as large amounts of data is processed by this code.
So imagine you have 2GB buffer allocated by using this code on a system that has 4KB pagesize. This would result in 524288 nodes. Each node would be stored in two lists, in first one they're last-head and in the other they're last-tail.
When the buf_free_datas is called for this buffer, it will walk totalnodes - index pagealign nodes for each of the released nodes. First iteration is (524288 - 1) "unnecessary" node walks, second (524288 - 2) and so forth. In other terms "sum of all integers smaller than itself", so in total totalnodes * (totalnodes - 1) / 2 extra operations.
This gives 137438691328 iterations.
alcinnz
boosted

#include would read the named file & concatenate into the output string preceded by a #line directive. #embed would work similarly, but reformats the read bytes into hexadecimal literals.
#define would extract the identifier & parse the following optional argument list & body removing (escaped) newlines to load into a "macro" table.
Non-preprocessor lines would be scanned for these macros' identifiers to perform a find & replace, recursing to handle substitute in parameters.
2/3?
#include would read the named file & concatenate into the output string preceded by a #line directive. #embed would work similarly, but reformats the read bytes into hexadecimal literals.
#define would extract the identifier & parse the following optional argument list & body removing (escaped) newlines to load into a "macro" table.
Non-preprocessor lines would be scanned for these macros' identifiers to perform a find & replace, recursing to handle substitute in parameters.
2/3?