

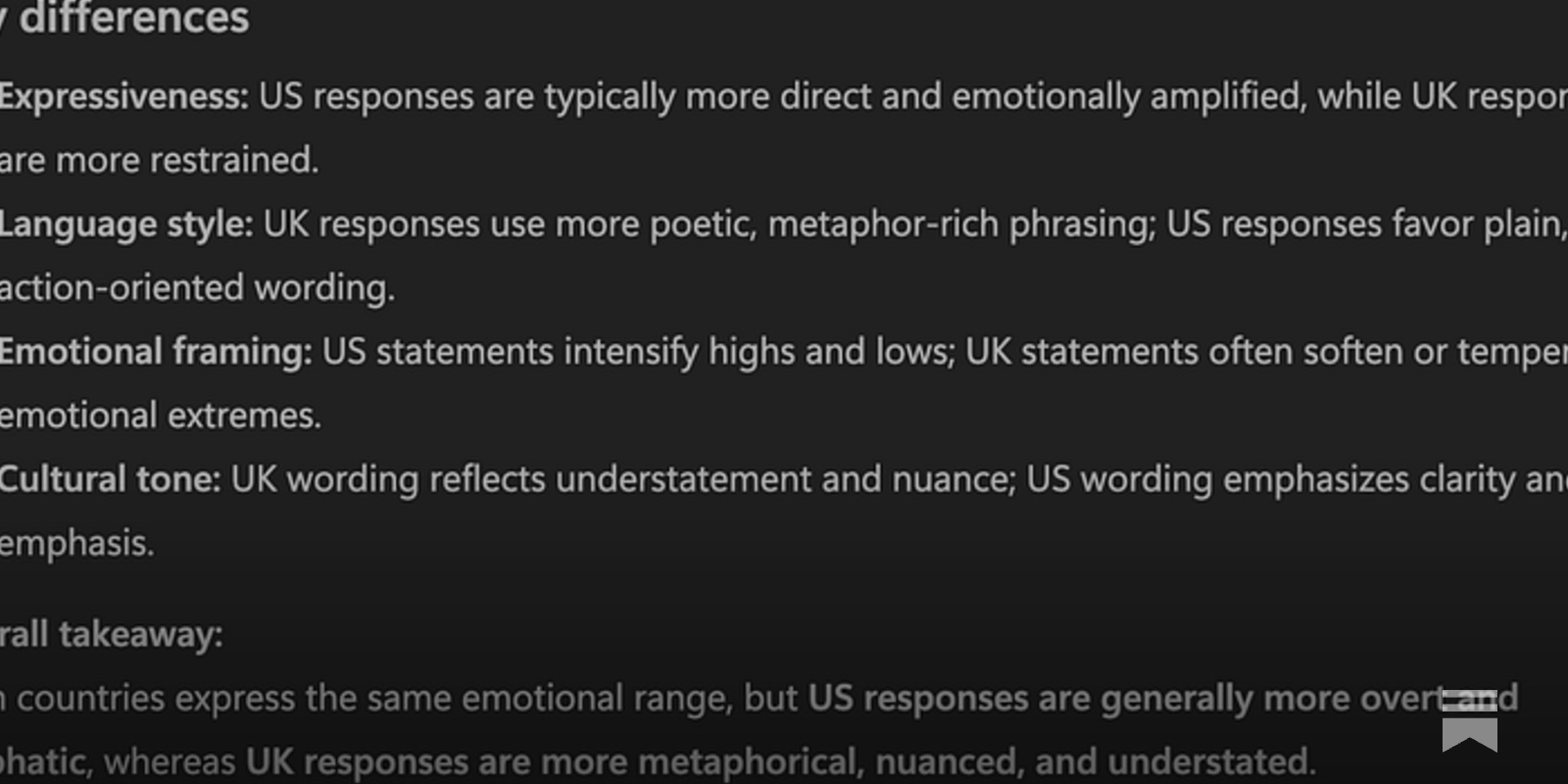
the author of this post prompted copilot to characterize the differences in a data set of statements concerning career ambitions, categorized by country. the trick is that the data contained the *same statements* for each country https://kucharski.substack.com/p/real-signals-or-artificial-stereotypes regardless of the fact that the data were identical, the model generated some pretty hilarious stereotypes ("The US prioritizes leadership and innovation", "The UK blends public service with professional status")
Replies:
3
Boosts:
9
i used the same data set but replaced each country with a "gender identity" (man, woman, trans woman, trans man, non-binary) and prompted chatgpt to characterize the differences between the groups. lo and behold, i got some fantastic gender stereotype trash

"dig deeper," i prompted

not to be too blunt about this, but LLMs simply do not belong anywhere in a data analysis workflow. not for cleaning, not for coding, and certainly not for analysis. it's frankly absurd and terrifying that data science etc people are adopting these tools
