

*How many "bugs" can some finite chunk of code possibly have? Will it ever run out of bugs? Can models just invent new forms of bugs to patch indefinitely?
Post
Replies:
4


@bruces I've been using Opus to look at an OSS project I work on (something like a couple million lines of code, almost three decades old), and it's finding a large number of issues. At least half the stuff it finds is legitimately a security issue, but quite low-grade issues. Stuff that would require some kind of elevated access to already exist to take advantage of it. We'll fix them, because it's noise for future scans with LLMs, but it's not something we're urgently rushing out to users.
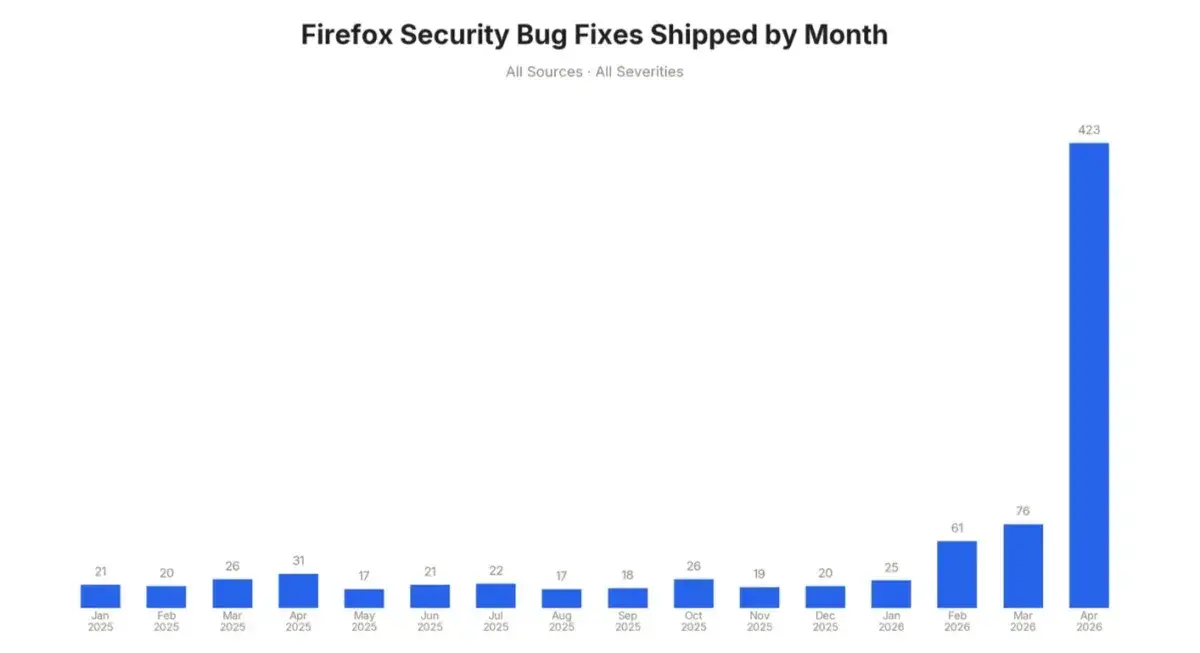
@bruces I imagine it's similar for Firefox. Though, also, in our case it found a legitimately serious privilege escalation bug that we treated with more urgency. I'm sure Firefox also has some serious issues lurking in all those millions of lines of decades old code. A browser is huge, loads of code for bugs to hide in.

@swelljoe @bruces yes, the issues are a very mixed bunch in term of severity. Additionally when it came to the components I'm in charge of the issues that were reported always had two things in common: they were in old code and it was C++ code. I've had zero reports in rust code, and we landed quite a bit of it. This is just a datapoint though, I didn't go through all the bugs in other components to verify it.

@bruces so far, the AI tools have not found *new forms* of bugs. They find the same forms, just new instances. So in theory they could eventually run out... but we keep adding new bugs, and the tools are still far away from finding *all* issues.
