

@db_geek gonna be honest, that's pretty underwhelming 🫠
Post
Replies:
10


In return for being a named sponsor the I can just about cover that particular expense 😁
@simonzerafa @openbenches
Ultra Gold Platinum Exclusive Sponsors start at 50p 😁
OK, I'm in. More than happy to sponsor at that level or up to £10 to cover anticipated future expenses 🙂
@simonzerafa
That's incredibly kind of you 🥰
We have donation options at https://openbenches.org/support
GitHub Sponsors or OpenCollective
https://github.com/sponsors/openbenches
https://opencollective.com/openbenches


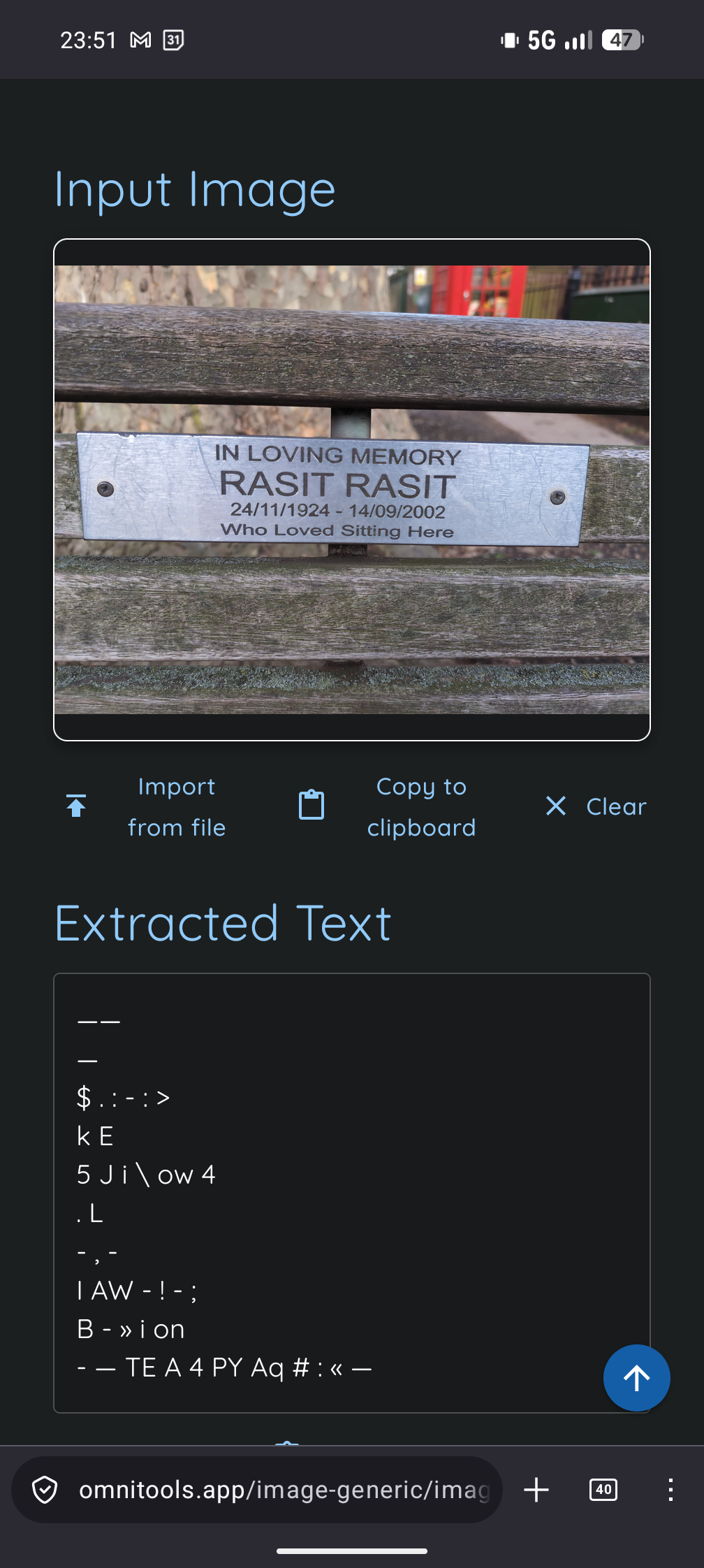
I don't know, what OmniTools is using for OCR in the background.
It is easy to run it locally.
For testing purposes also a demo is available:
https://omnitools.app/image-generic/image-to-text

@db_geek gonna be honest, that's pretty underwhelming 🫠
Yes, that looks really bad.

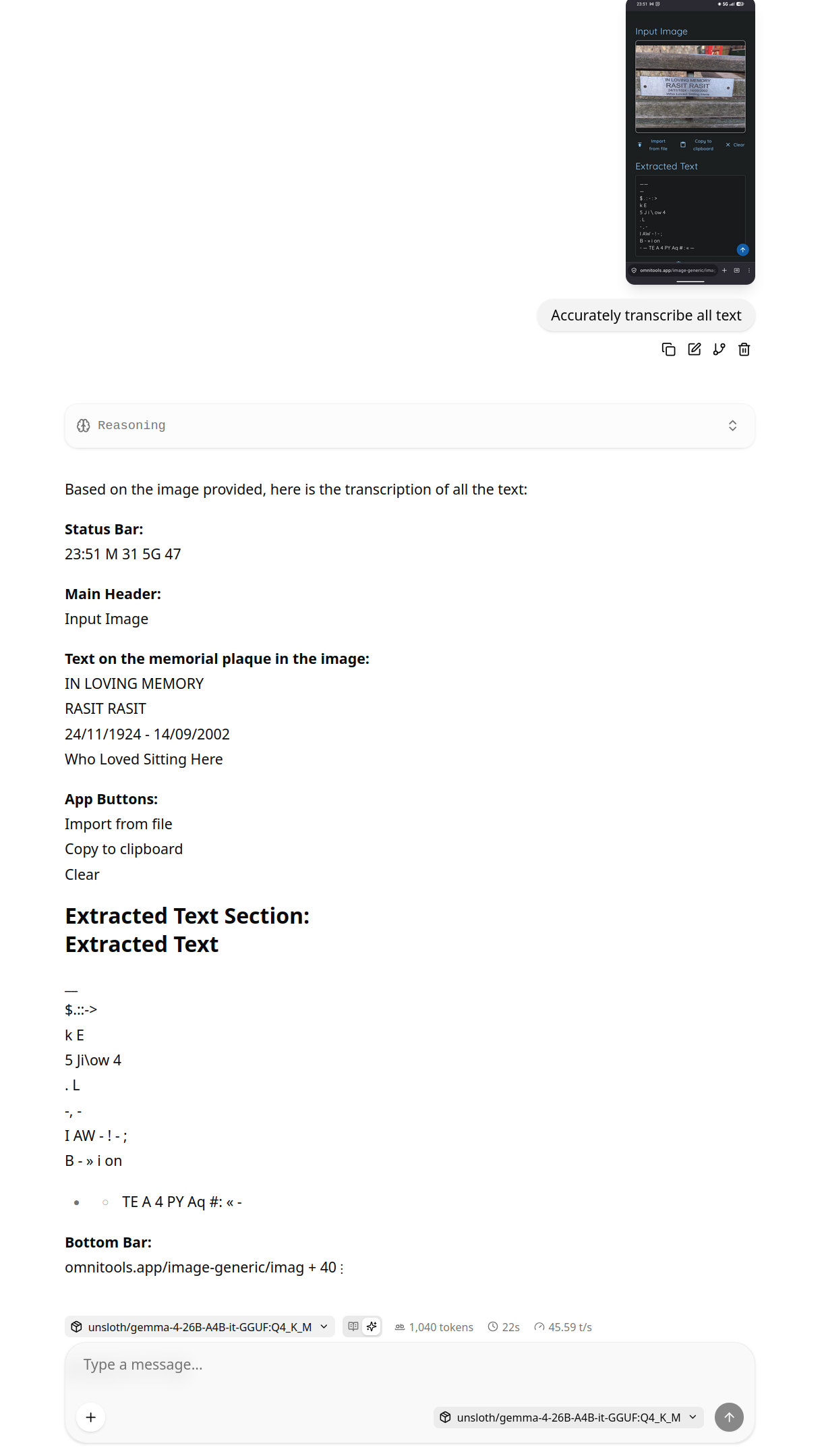


@Edent I am currently doing a lot of vision work on documents, PaddleOCR for a fully local setup is doing decently, might be worth looking into.
Compared to Teserract its setup for scene text detection, so it got a chance to work for benches :)
@fallenhitokiri
Oooh! Paddle's API is both generous and accurate.
It's a pity it is so slow. Not sure if that's a latency to China thing, or just the speed of the model.
Will keep trying. Ta!
