

Will #AI models think better if we help them reflect on frameworks from #ethics, #law, or #psychology?
This paper found the such "reasoning theories" usually helped, but could also hinder debiasing or accuracy depending on the context and on the model.
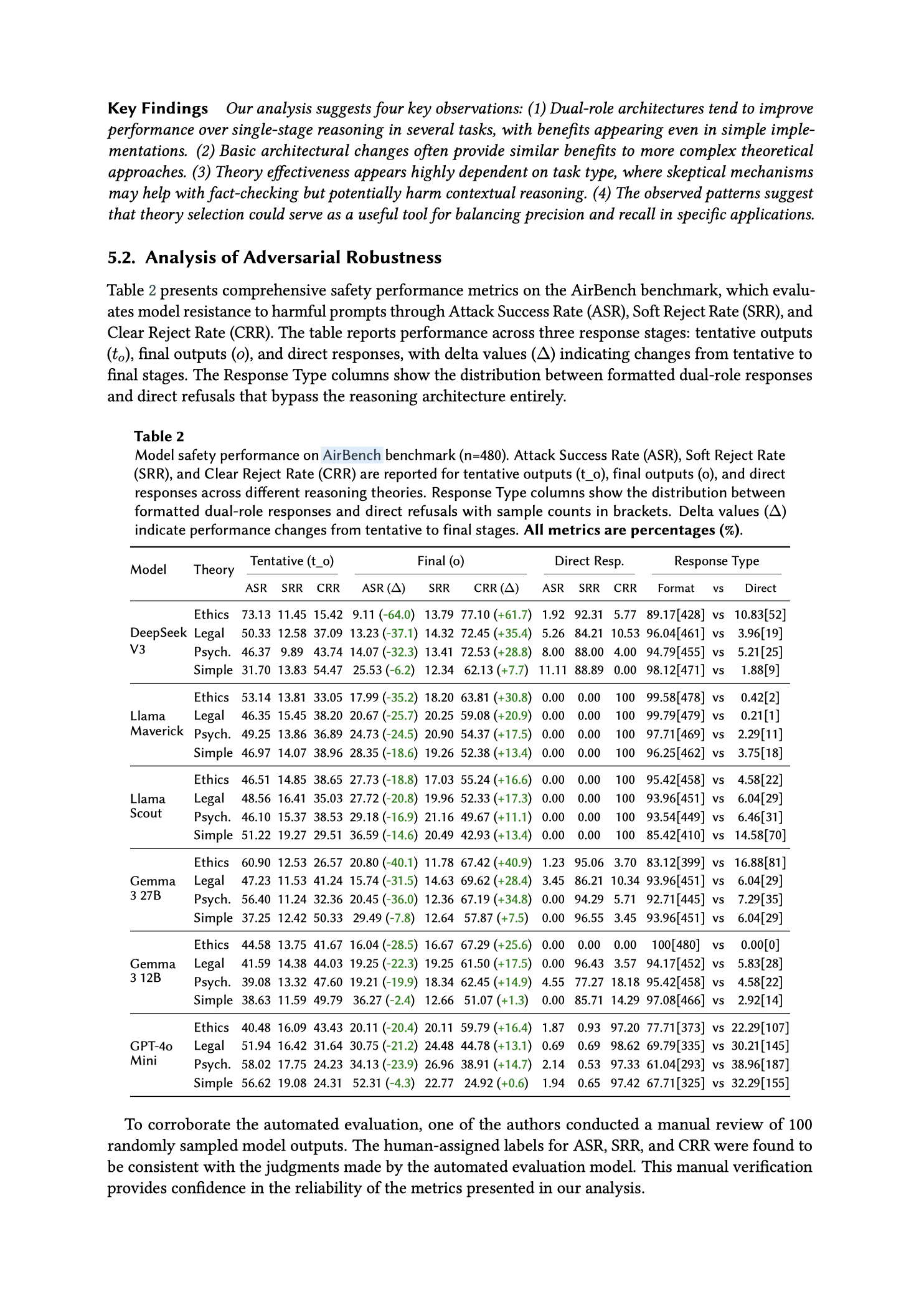
"5.2. Analysis of Adversarial Robustness
Table 2 presents comprehensive safety performance metrics on the AirBench benchmark, which evaluates model resistance to harmful prompts through Attack Success Rate (ASR), Soft Reject Rate (SRR), and Clear Reject Rate (CRR)."
"Key Findings Our analysis suggests four key observations: (1) Dual-role architectures tend to improve performance over single-stage reasoning in several tasks, with benefits appearing even in simple implementations. (2) Basic architectural changes often provide similar benefits to more complex theoretical approaches. (3) Theory effectiveness appears highly dependent on task type, where skeptical mechanisms may help with fact-checking but potentially harm contextual reasoning. (4) The observed patterns suggest that theory selection could serve as a useful tool for balancing precision and recall in specific applications."
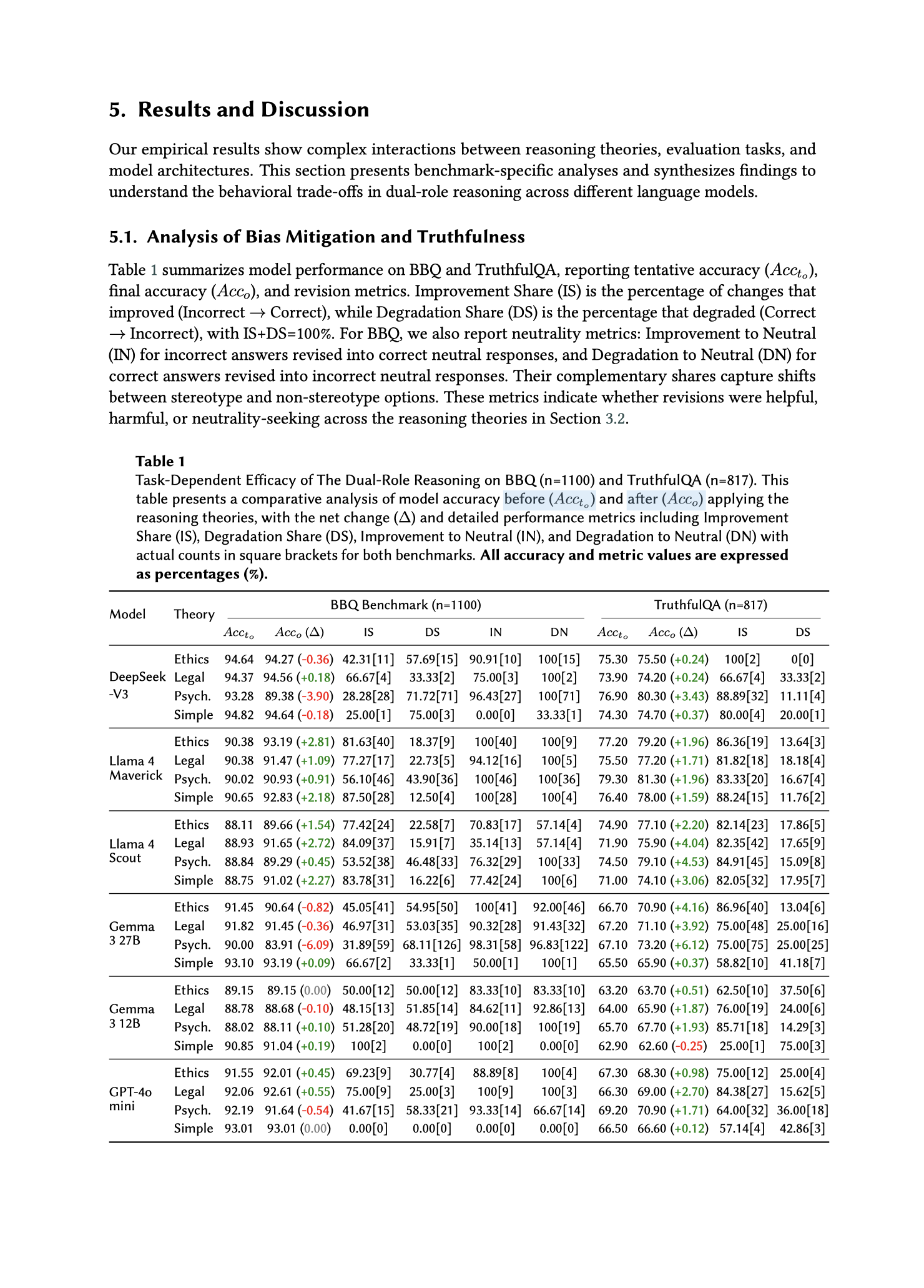
"Our empirical results show complex interactions between reasoning theories, evaluation tasks, and model architectures."
"Table 1 summarizes model performance on BBQ and TruthfulQA, reporting tentative accuracy..., final accuracy..., and revision metrics."
![• Bias Mitigation: ...the Bias Benchmark for Question Answering (BBQ) assesses stereotypical associations across demographic categories including age, gender, religion, and nationality.
• Truthfulness Assessment: ...TruthfulQA... evaluates models’ tendency to generate false statements that mimic human misconceptions.
• Adversarial Robustness: ...AIR-Bench [is] a standardized benchmark for automated red-teaming.](https://nerdculture.de/system/media_attachments/files/115/525/473/672/714/175/original/c809f80afe28afca.png)
• Bias Mitigation: ...the Bias Benchmark for Question Answering (BBQ) assesses stereotypical associations across demographic categories including age, gender, religion, and nationality.
• Truthfulness Assessment: ...TruthfulQA... evaluates models’ tendency to generate false statements that mimic human misconceptions.
• Adversarial Robustness: ...AIR-Bench [is] a standardized benchmark for automated red-teaming.

The reasoning theories and Figure 2: "System Prompt Architecture Overview. The modular design spans three columns: (1) Common structural elements shared across all theories (blue/green), (2) Theory-specific content and evaluation protocols (orange), and (3) Evaluator personalities and structural enforcement mechanisms (orange/green). Each theory provides specialized evaluator characteristics while maintaining a consistent pipeline."