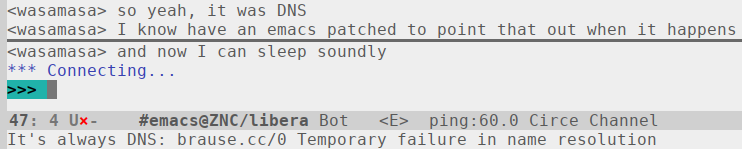
With all the easy IRCv3 capabilities implemented, I looked into some of the harder bugs plaguing Circe and touched the reconnect logic in lagmon/pingmon. Had a hunch that the reason reconnects sometimes fail with an unhelpful error (claiming among other things that the service/port number of the affected socket is 0) is #DNS and confirmed it by patching #Emacs to show a clearer error message (and raise a more specific error) when it's indeed DNS.
Remaining problem: Merely throwing/catching a DNS error is not enough as that makes the network process enter a "deleted" state (whatever that means) and any operations on the object fail, so that case needs to be detected to create a new one (which is basically what I'm doing when manually executing M-x circe-reconnect-all). Then the bug may be fixed for good...