

By randomizing #LLM prompts and analyzing moral #keywords via co-occurrence #networks and hierarchical clustering, @andrewpiper uncovers latent “moral communities” across 20th–21st century #English-language #fiction.
https://doi.org/10.48694/jcls.4168
Discussion
Loading...
Discussion
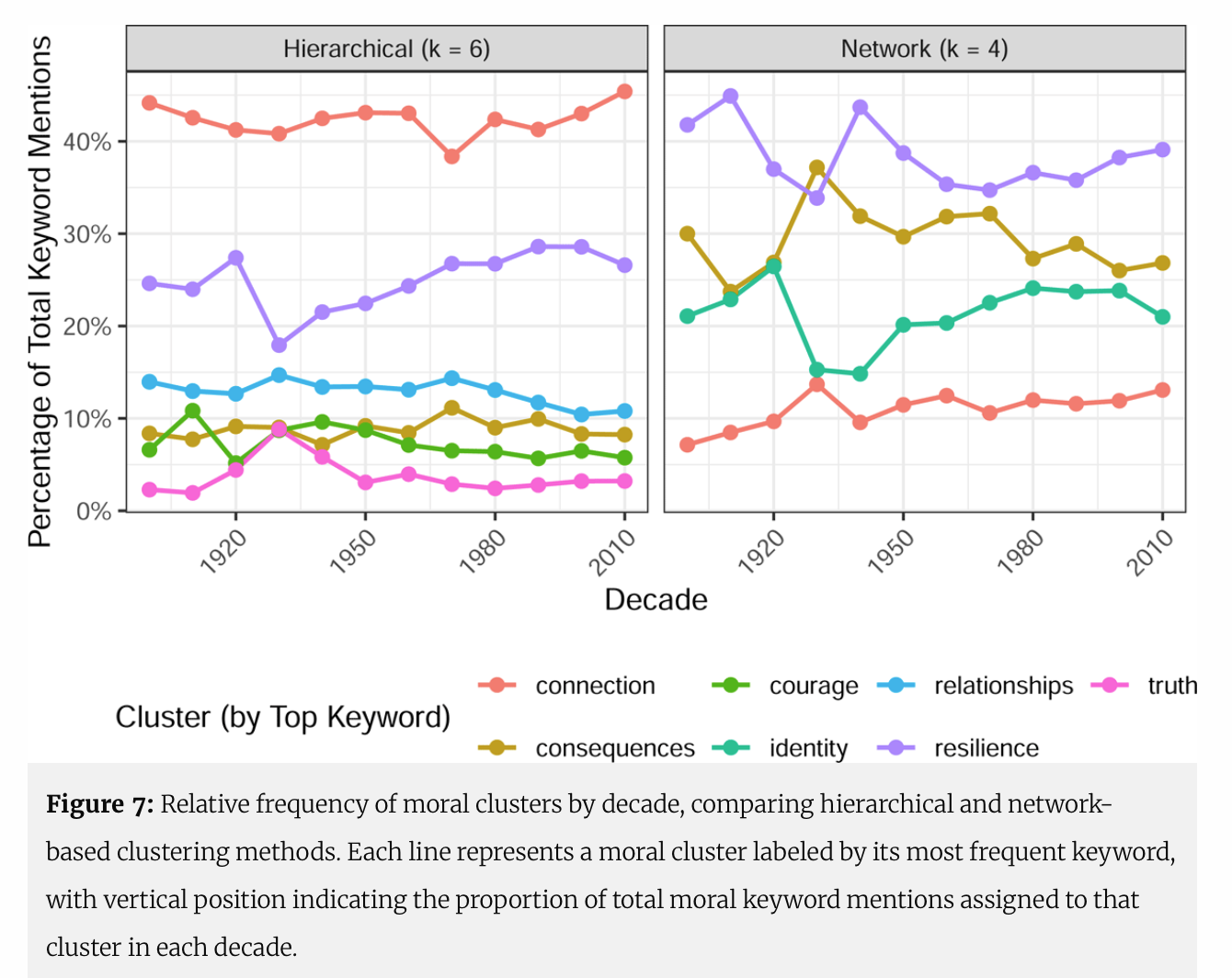
As always: #OpenData and #OpenCode persistently available at: https://doi.org/10.5683/SP3/0EYY0T.
And the article: https://doi.org/10.48694/jcls.4168
bonfire.cafe
A space for Bonfire maintainers and contributors to communicate
Automatic federation enabled