

When a crawler requests a page that is managed by an RSL license from your website, it must include a valid RSL License Token for the page in the HTTP header using the new proposed License RFC 7235 HTTP Authentication scheme.’
Discussion
Loading...
Post
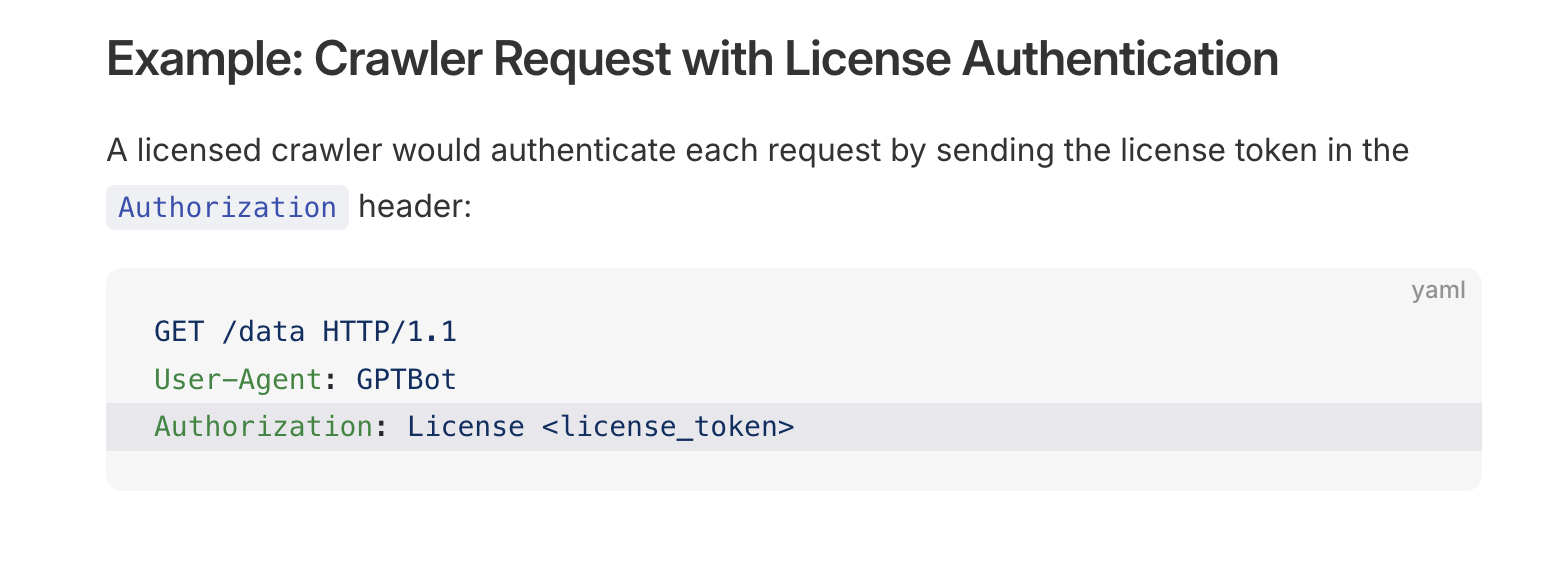
‘RSL adds licensing capabilities to the RSS feed format, enabling publishers to create standardized, public catalogs of their licensable digital assets. When used in an RSS feed, RSL functions as an RSS module that adds licensing capabilities to the RSS item element’
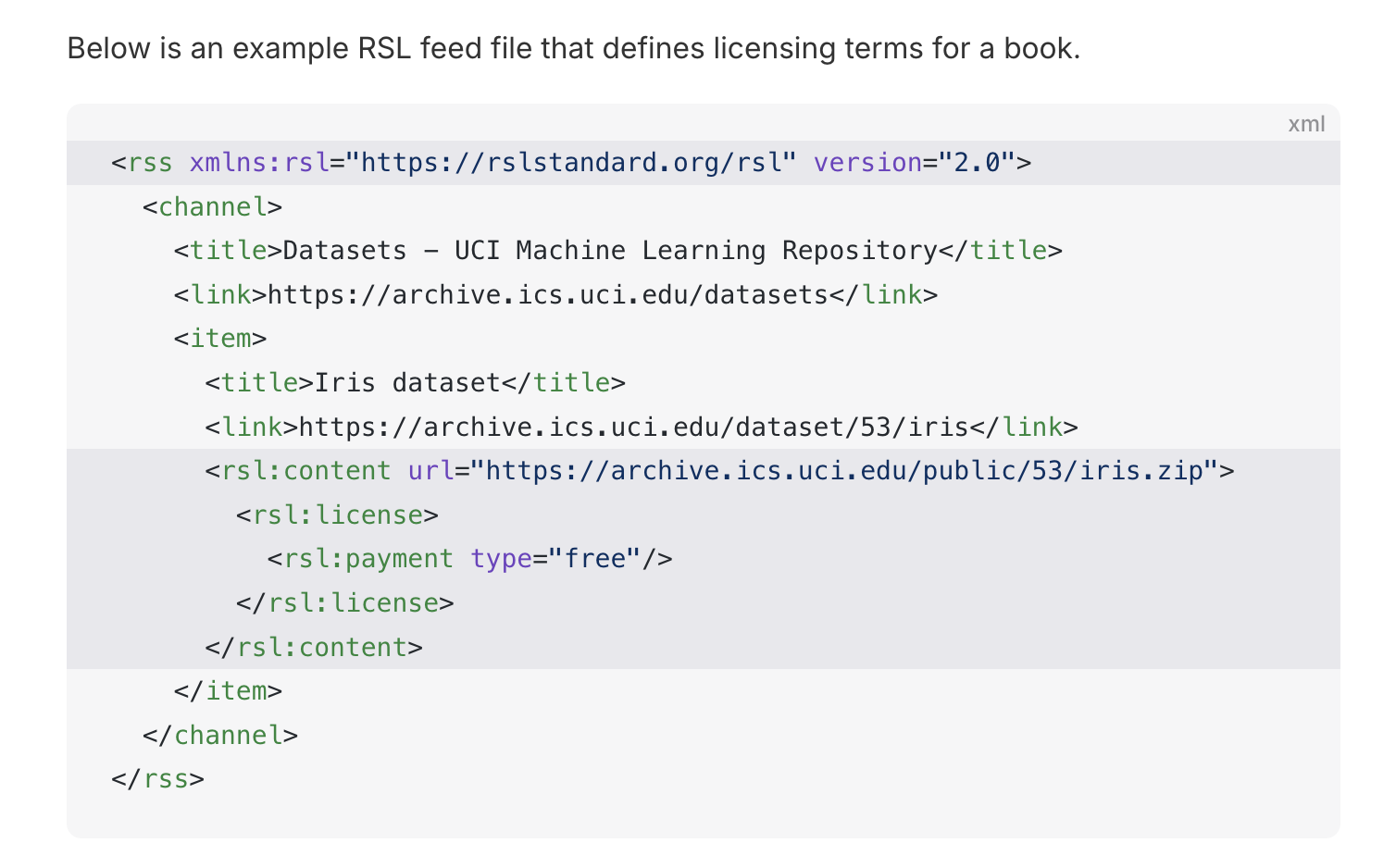
When a crawler requests a page that is managed by an RSL license from your website, it must include a valid RSL License Token for the page in the HTTP header using the new proposed License RFC 7235 HTTP Authentication scheme.’




@tchambers @js I'm going to look into it.
Hard to imagine how this could work while still allowing usage by regular people AND avoiding scrapers that pretend to be regular people. But let's see.
@tchambers @js
Ok I've looked into it.
This is just robots.txt on steroids in the sense that it's entirely opt-in and only binds law-abiding actors. It has no answer to the badly-behaved scrapers that ignore robots.txt and overwhelm our instances.
Having said that it will still be great to have a way to bill the 'good' crawlers and I appreciate the lightweight and simple methods they propose. It might work.
Or it could just mean the incentive for crawlers to spoof user-agents is higher...
@tchambers @rimu
other than the server and client work to implement both sides, in podcasting there is also the question of free and cutoff vs paid and full-length versions of the same episode, and also free with-ads vs paid without of the same episode
ideally in the same feed or some defined relationship between the paid and free episodes (best listener exp) - this is still very early with other payment schemes and would have to do a bit of work with this scheme as well
cc @dave
@tchambers @rimu @dave
personally I am still very dubious on these proposals, and view it as walking through a one-way door that I'm not sure we want to walk through in a large-scale way without a ton of experimentation first
this one is only interesting in that it has Reddit on board and a few others - and to me the especially-grating shameless comparisons to RSS
bonfire.cafe
A space for Bonfire maintainers and contributors to communicate
Automatic federation enabled