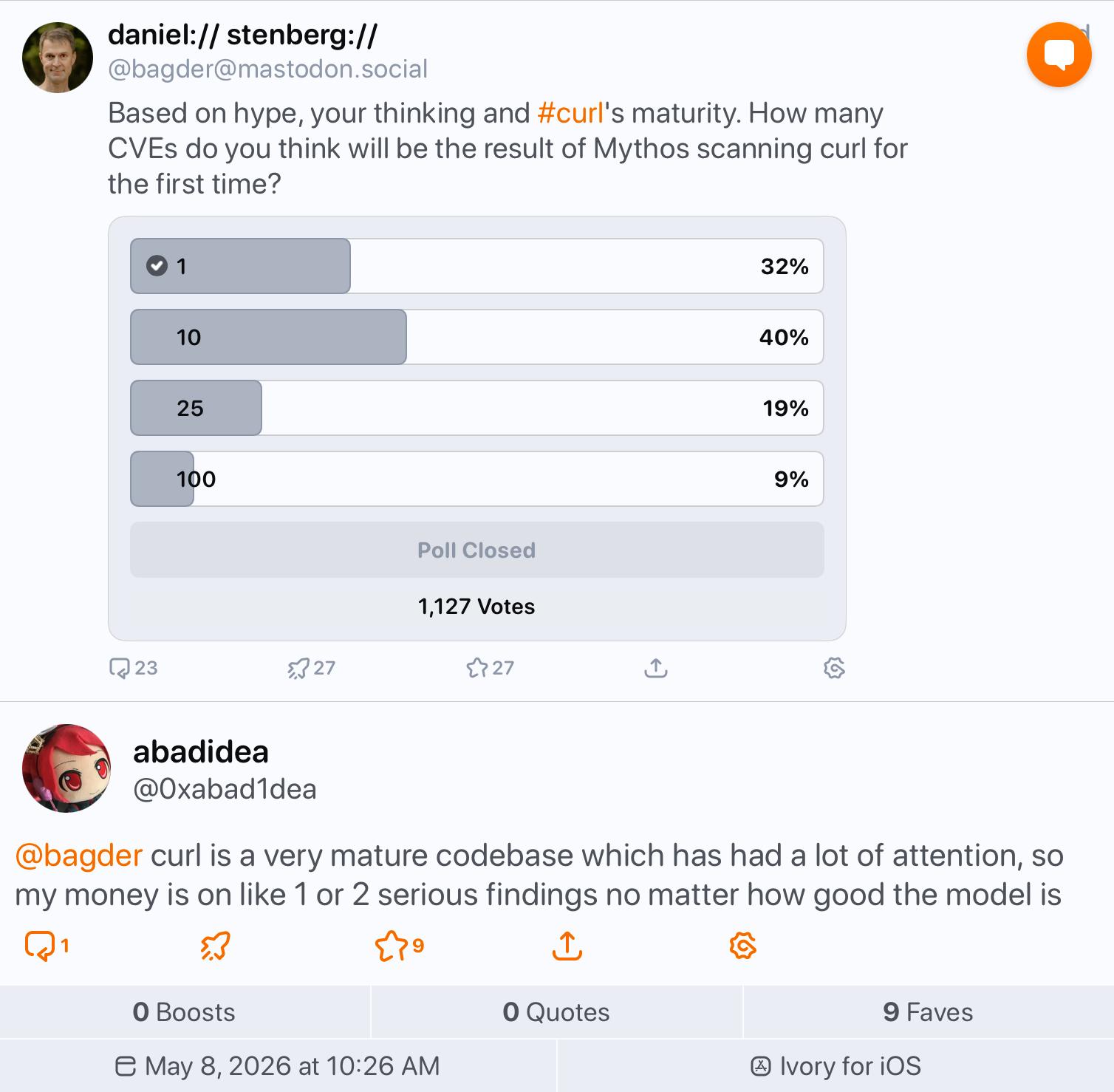
RE: https://mastodon.social/@bagder/116554421875449945
called it 😌 one (1) low-severity CVE found when applying mythos to a mature and well-maintained C code base
Discussion
RE: https://mastodon.social/@bagder/116554421875449945
called it 😌 one (1) low-severity CVE found when applying mythos to a mature and well-maintained C code base
")
I’m really curious about why. A few possibilities:
Mythos is trained to look for specific vulnerability-shaped patterns, the curl developers are also trained to look for those patterns and so have caught those things.
Mythos is two steps, one that looks for vulnerability-shaped things, the other that builds a PoC. The previous Anthropic models had a massive false positive rate for the former step. Mythos does as well for curl and they blew their token budget trying to find PoCs for things that were not real bugs before they got to one that is.
As above, but the shape of curl’s codebase makes LLM-generated PoCs unusually hard.
A bunch of humans have been using LLM-assisted tools on curl for the past year and have found all of the low-hanging fruit for these tools already.
Curl doesn’t have many vulnerabilities.
Mythos is 95% marketing and is just not very good.
@david_chisnall I think we can rule out token budget issues, because the point of the Mythos preview phase is that enormous amounts of token budget are being "donated" as a marketing tactic
I think (genuinely with consideration, not merely as a blanket anti-AI assertion), that curl is just about as mature and battle-tested as a C project can be, with continuous maintenance – and that no amount of Model Power can overcome good engineering and magically summon flaws into being. I'm sure mythos can find tons of stuff in immature, slapdash work.
@0xabad1dea In some other posts, they've indicated amounts that they spent, on the order of $20K of tokens to find one bug. I doubt they're letting curl burn unlimited tokens. If it burns $200K and doesn't produce a PoC, I'd imagine they give up.
@david_chisnall @0xabad1dea and that's 20k at the current magic money subsidies token price right?
@david_chisnall @0xabad1dea I think I would believe any of these except "curl is shaped in a way that LLMs are bad at" (paraphrasing) - I don't think there's anything particularly strange about the way curl is laid out? and with how widely distributed it is, I would sort of assume that models have "seen" it a lot in training
@david_chisnall @0xabad1dea (if that did turn out to be a large factor here, it's still not great for Mythos, since every C project layouts are like snowflakes)
I don’t really have a good intuition for what the PoC-producing bit of Mythos is good at. It’s trying to generate code that triggers bugs. As I understand it, it can run the PoC and test it, so it has some aspects of a fuzzer, but I’m not sure how it’s state-space exploration will work. I would imagine that, for curl, there are a lot of examples of correct API use in its training set. Does that mean it gets stuck trying to produce API-misuse examples because the search space is skewed away from them?
@david_chisnall @0xabad1dea Appropriate for its name, really

Install bonfire.cafe
Get the full app experience